
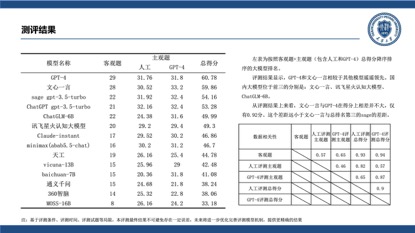
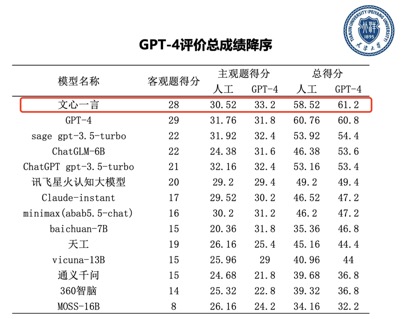
尤其值得关注的是,在此次评测中,天津大学引入GPT-4对参评模型的主观题回答进行了打分,结果显示,在GPT-4看来文心一言生成的中文内容质量更高。相比人工评价,在基于GPT-4的自动评测中,文心一言的总得分一举超过GPT-4,跃居榜首。
天津机器学习重点实验室负责人、天津大学胡清华教授表示,“基础智能模型有望重塑人工智能的发展模式,国内外大模型如雨后春笋般大量涌现。全面准确评价此类模型是推动和规范其健康发展的基础,为使用者在选择和应用大模型时提供参考。可以看到,百度文心一言在评测中展现了国产大模型的强大实力,中国的大语言模型在短期内取得巨大发展,正在逐步赶超国际类似的模型,甚至在某些指标上实现了局部超越。未来,期待国产大模型能够取得更大突破,可以赋能社会经济发展,助力我国科技高质量自立自强。”
据了解,参与本次评测的大模型包括GPT-4、ChatGPT gpt-3.5-turbo、Claude-instant、Sage gpt-3.5-turbo等国外大模型,以及百度文心一言、阿里通义千问、讯飞星火认知大模型、ChatGLM-6B、360智脑、MOSS-16B、MiniMax、baichuan-7B等国产大模型。评测使用一套涵盖知识问答、语言表达、逻辑推理、常识问答、文本问答、机器翻译等不同领域知识、包含多种题型的中文综合性试题,通过多维度得分结果,清楚了解不同模型的擅长领域和综合能力优劣。
结果显示,国产大模型以文心一言为代表,在知识问答、语言表达、逻辑推理、常识问答等方面表现出色。相比其他国产大模型,文心一言更具优势,展示了更强大的综合能力。尤其在中文语言表达上,文心一言相比GPT-4和其他国内大语言模型明显更优质。此外,本次评测中,文心一言在计算机、医学、法律和教育等领域的得分率高,为大语言模型在相关行业的落地提供了技术基础。
近期,国内外多家调研机构、权威媒体和高校等发布大模型评测报告,从结果来看,文心大模型3.5版支持下的文心一言中文能力突出,甚至有超出GPT-4的表现;综合能力在评测中超过ChatGPT,遥遥领先于其他大模型,稳居国内第一。有专家指出,大模型正在进入规模可复制的产业落地阶段,在关注大模型评测的同时,更要关注大模型的落地生态。百度文心在大模型生态的构建上具备先发优势。
公开资料显示,文心大模型已经拥有中国最大的产业应用规模,目前有15万家企业申请接入文心一言测试。最新数据显示,百度有超过750万开发者基础,20万企业生态基础,多层次开展大模型人才培训、企业赋能、开发者运营。百度还设立10亿创投基金鼓励大模型创意、繁荣大模型生态,不到1个月时间吸引近1000个项目参与角逐,参赛团队表示,百度打响了中国大模型的第一枪,百度在资金、技术、业务等方面的全面扶持,大幅降低了大模型行业的入局门槛,为大模型应用创业团队注入了强劲动力和信心。

